MLIR:新建一个Dialect(三),待编译的mlir文件
文章来自微信公众号“科文路”,欢迎关注、互动。转发须注明出处。
Multi-Level Intermediate Representation(MLIR)是创建可重用、可扩展编译器基础设施的新途径。本文为第 9 期,继续介绍一个简单的 MLIR Dialect.
转载请注明出处!
MLIR 项目的核心是 Dialect,MLIR 自身就拥有例如linalg,tosa,affine 这些 Dialect。各种不同的 Dialect 使不同类型的优化或转换得以完成。
接上回,本文继续新建一个 Dialect的内容。本文开始解析项目的各个实现部分之一——待编译的 .mlir 文件。
项目内容
mlir-hello 项目的目标就是使用自建的 Dialect 通过 MLIR 生态实现一个 hello world,具体做法为:
- 创建
hello-opt将原始print.mlir(可以理解成 hello world 的main.cpp)转换为print.ll文件 - 使用 LLVM 的 lli 解释器直接运行
print.ll文件
今天先通过 print.mlir 理解一下 MLIR 世界的语法,该文件在 mlir-hello/test/Hello/print.mlir
1 | func.func @main() { |
print.mlir 文件解读
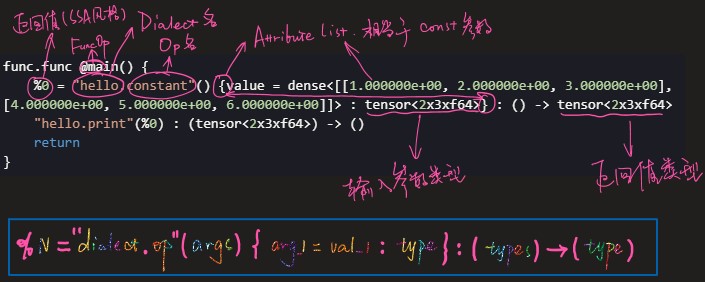
- 在
@main这个FuncOp里,首先定义了一个hello.constant存放于%0 %0的内容为一个 $2\times3$ 的二维 const 的tensor,数值类型为float64- 在第二个自定义的 Dialect Op
hello.print中,%0作为参数被传入(打印)
图最下的蓝框内为 MLIR 的一般形式,它与 SSA 相似,可参考MLIR:静态单赋值,SSA。更多语法信息参看MLIR:LangRef。
可以猜测,该代码最终的效果为“打印出这个二维矩阵”。
本期结语
本文对 mlir-hello 项目的源代码文件 print.mlir 进行了学习,通过自定义的 Dialect 实现可以将该文件“编译”为 LLVM lli 解释器可直接运行的 .ll 文件。我们下期继续。
都看到这儿了,不如关注每日推送的“科文路”、互动起来~
至少点个赞再走吧~
MLIR:新建一个Dialect(三),待编译的mlir文件