MLIR:编译器基础架构重定义
文章来自微信公众号“科文路”,欢迎关注、互动。转发须注明出处。
MLIR: 编译器基础架构重定义
MLIR(多级中间表示)是语言(如 C)或库(如 TensorFlow)与编译器后端(如 LLVM)之间的中间表示 (IR) 系统。允许不同语言的不同编译器堆栈之间的代码重用以及其他性能和可用性优势。
MLIR 由 Google 开发为一个开源项目,主要是为了改进 TensorFlow 在不同后端的支持,但通常可用于任何语言。
背景
要了解 MLIR 的适用范围,需要简要概述 C、Java 和 Swift 等常用语言的编译器基础架构,然后继续介绍 TensorFlow 的编译器基础架构。这样,MLIR 的原理和可交付成果的想法就很清楚了。
编译器架构情况:
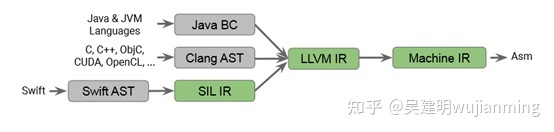
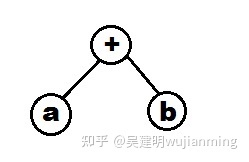
从 C 的编译器基础结构开始。C 编译器接收 C 代码,转换为抽象语法树 (AST),然后将其转换为 LLVM IR。AST 是一种树数据结构,其中节点表示算子等代码组件,叶节点表示数据。例如,像 a+b 这样的代码语句的抽象语法树如下:
随后,抽象语法树被转换为 LLVM IR(中间表示)。LLVM 是一种编译器基础架构,可将 LLVM IR 转换为机器代码。LLVM 是一种常用工具,是最流行的语言(如 C、C++、JAVA、Swift 等)的一部分。
所以,C 代码的流程如下:
- C 代码由 C 编译器(如 GCC)转换为 Clang AST
- Clang AST 通过 C 编译器(如 GCC)转换为 LLVM IR
- LLVM IR 由 LLVM 转换为机器码
C 的这种编译策略存在一些问题,例如:
- 在 AST 中,将代码语句链接到代码行号或源代码的信息丢失了,因为 AST 无法存储此类信息。导致无法指向源代码的错误。一个常见的例子是,当发生 segmentation fault 时,错误信息并没有说明是源代码中的哪一行导致了这个问题。
- 由于 C 代码直接转换为 AST,不会进行特定于语言的优化。事实上,如果开发了 C 库,则在此流程中无法在编译器期间进行特定于库的优化。
Java 和 Swift 等语言采用了不同的方法来解决这个问题。
Java 是第一个解决这个问题成功的语言。Java 的方法是将 Java 代码转换为 Java 字节码 (JavaBC),是 Java 的内部表示。正是在这种表示进行了 Java 特定和库特定的优化。在此之后,Java BC 被转换为 LLVM IR,后者被 LLVM 转换为机器代码。因此,Java 的方法是避免创建 AST,是任何程序的通用表示,因此创建了自己的格式,不仅解决了 C 的问题,而且使 Java 成为第一个独立于平台的语言。
Java 方法的一个问题是变得非常复杂,需要深入了解 LLVM 才能充分利用。这将现有资源发挥到极致,以获得最佳优化。
其它语言复制 Java 的技术是一个问题,所以后来,Swift 提出了自己的方法,并被广泛采用。
Swift 代码被转换为 AST,其中 Swift 特定表示被转换为 Swift 的内部表示。正是在这一点上,所有语言特定的优化都完成了。随后,Swift IR 被转换为 LLVM IR,后者被 LLVM 获取并转换为机器代码。
这是一种相对简单的方法,解决了所有 C 的原始问题。在功能上,与 Java 的方法相同。Swift 的方法变得非常流行,并被改编成 Rust 等新语言。
此时的主要问题,每当创建一种新语言时,必须再次进行所有优化,例如程序流程优化、数据结构优化等(以前的语言已经完成)。唯一不同的是语言特定的优化。LLVM 负责机器级优化。因此,必须为每种语言再次创建整个管道。
如果仔细观察,语言仅在操作抽象和内部语言特定优化方面有所不同。为了帮助创建新的语言和库,Google TensorFlow 团队决定创建 MLIR(多级中间表示)。
MLIR 提出
实际上,这个问题是在 TensorFlow 中遇到的,谷歌并没有专门为 TF 解决这个问题,而是决定一劳永逸地修复编译器基础架构。
TensorFlow 的编译器基础架构:
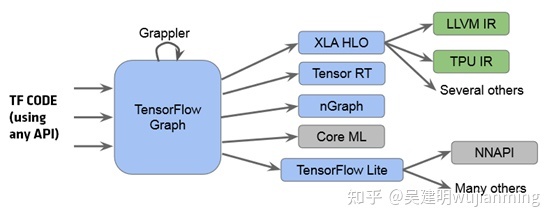
流程如下:
- 可以使用 API 之一(如 C++ 或 Python)来编写 TensorFlow 代码
- TensorFlow 代码被转换为 TF 图,Gappler(TensorFlow 中的一个模块)进行图级优化,包括几个机器学习特定的优化,如算子融合。
- 在此之后,TF 图被转换为其后端之一(替代 LLVM)的众多内部表示 (IR) 之一。
- TensorFlow 有许多后端,如 XLA(用于 TPU)、TF Lite(用于移动设备)等
问题是对于每个路径(如 XLA 和 TF Lite),开发人员必须重新实现所有优化,并且大多数优化是通用的,但代码重用是不可能的。这个问题将通过 MLIR 解决。
因此,MLIR 的流程如下图所示:
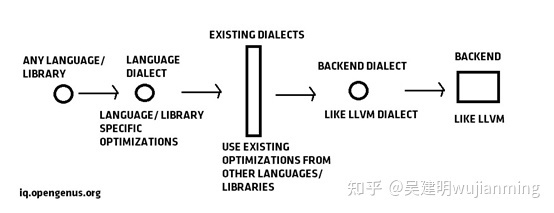
概括:
- 不同语言的相同编译器基础结构,不可重用
- 类似于 Swift 和其他语言中的编译器基础结构
- tensorflow 支持许多具有不同 IR 的后端,无需代码重用
- 目的是增加代码重用以快速适应新的硬件后端
- 中间 IR 用于捕获数据流信息并应用优化、比 LLVM 更好的源代码跟踪、灵活的设计、重用 LLVM 进行机器代码生成
使用 MLIR 的优势
- 默认情况下源代码位置跟踪
- 默认情况下,所有功能都在多核上运行(使用 OpenMP)
- 更好地重用编译器堆栈的代码(用于新库和硬件),重用其它语言完成的优化
- 通过开发 CIL IR 为 C 提供更好的编译器堆栈
- 对于 TensorFlow,一条路径中的优化可以在其它路径中重用,从而实现大量代码重用。
内部关键思想
MLIR 的主要思想是:
- 没有预定义的类型或指令。这允许开发人员自定义数据类型和指令抽象
- 没有预定义的操作
- MLIR 中的基本对象是一种方言 dialects,从实现的角度可以认为是一个类
- 需要定义指向 C++ 代码的方言 dialects,方言 dialects 就像自定义语言的类
- 方言 dialects 有 3 部分:函数名、输入参数列表、输出参数列表
- 对于每种方言 dialects,默认功能如类型检查、映射到 LLVM IR
- MLIR 默认支持线性代数运算,例如方言 dialects 之间的类型检查
- 语言被转换为带有方言 dialects 的形式
- 在这种形式(方言 dialects 集)上,执行优化
- 经过各种级别的 lowering,方言 dialects 可以直接转换为 LLVM IR
- 在 MLIR 中更好地使用 OpenMP,所有信息都可用
- 默认情况下,所有功能都在所有内核上运行(更好的系统使用)
- (优于 LLVM)每个操作数都有一个源代码内存地址属性,直接指向发生错误的源代码行
- 将使用 XLA 基础架构进行性能分析和剖析。
应用
MLIR 用于改进 TensorFlow 编译器基础架构:
1. 通过源代码跟踪改进 TF Lite 的生成
编译流程如下:
- TF 代码
- 方言 dialects
- 验证 / 优化
- 用于 tf lite 后端的 tf lite 方言 dialects
2. 使用 MLIR 更改 XLA HLO 的路径
编译流程如下:
- tf
- 方言 dialects
- 验证 / 优化
- xla 方言 dialects
- xla 后端
它将重用来自 TF Lite 路径的一些组件
3. 使用 MLIR 支持新的编译器后端
当一个新平台 P 出现并且它有一个新的后端 B 时,然后转换 TensorFlow 代码通过使用 TF Lite 和 XLA 的现有代码,转换为现有的方言 dialects/IR。接下来,需要编写一个新的方言 dialects 集 / IR(针对平台进行自定义优化)和转换代码,转换为平台后端编译器所需的 IR。
MLIR 的使用使该过程更易于管理和快速。
其它应用
MLIR 是一种通用工具,可用于其它目的,例如:
- 通过 MLIR 插入新的 IR 来解决 C 和 C++ 代码的问题
- 新语言可以直接使用使用 MLIR 的现有语言的优化,因此开发新语言将变得容易和快速。
- 一旦使用 MLIR 的系统实施,一组编译技术的创新可以被多个组轻松使用
简而言之,LLVM 极大地创新了编译器生态系统,但现在 MLIR 通过利用 LLVM 的最佳部分实现更简单、更高效的编译器生态系统,从而进入了下一阶段。
都看到这儿了,不如关注每日推送的“科文路”、互动起来~
MLIR:编译器基础架构重定义