MLIR:概览
文章来自微信公众号“科文路”,欢迎关注、互动。转发须注明出处。
Multi-Level Intermediate Representation(MLIR)是创建可重用、可扩展编译器基础设施的新途径。
本文起,将结合工作经验对 MLIR 进行讲解。本文为开篇,内容来自Chris Lattner’s Homepage。
出发点
像 TensorFlow 这样的通用机器学习框架往往需要
- 许多不同种类的编译器来处理各种图一级的问题;
- 适配各式各样的加速器;
- 还需要大量的 “胶水 “工具来将一切联系在一起。
为了解决这些问题,2018 年 4 月,大神 Chris Lattner 和 Google 的一个小编译器团队开始了开始搭建这个世界级的系统——MLIR。
概览
想要做一个大一统的编译器看似是困难的。但 Chris 他们还是想到了“多级中间表示”这种设计方法。它旨在成为一种混合型 IR,可以在一个统一的基础设施中支持多种不同的要求。例如,
- 数据流图的表示
- 图的优化和转换
- 高性能计算
- 特殊 lowering
- 加速器特定的高级操作
- 图的量化
- Polyhedral primitives
- 硬件合成工具/HLS
也就是说,通过 MLIR 可以受益于其他 IR,完成各式各样的编译“中端”操作。
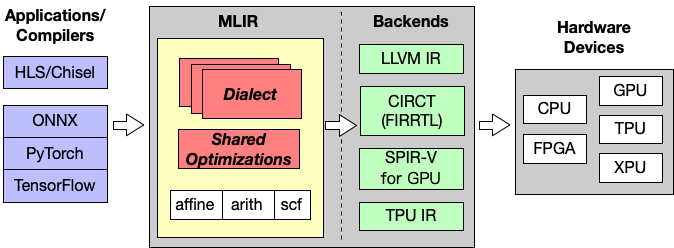
但是 MLIR 并不打算在更第一级别的“机器代码生成”上进行优化,因为这一部分的工作 LLVM 更适合。
现状
虽然 MLIR 还很年轻,但它已经在谷歌内部得到了快速和广泛的采用和部署,而且据说在整个行业中得到了广泛的应用,包括 SiFive、苹果、英特尔、微软、Nvidia、ARM 和许多其他项目(包括节省大量计算和运营成本的生产部署)。
MLIR 建立在 LLVM 社区之上,并被其他LLVM 项目所使用,如 Flang Fortran编译器、CIRCT 项目等等。
欲进一步了解可以阅读MLIR: A Compiler Infrastructure for the End of Moore’s Law。
都看到这儿了,不如关注每日推送的“科文路”、互动起来~
至少点个赞再走吧~