独立成分分析ICA
文章来自微信公众号“科文路”,欢迎关注、互动。转发须注明出处。
在统计学中,独立成分分析或独立分量分析(Independent components analysis,缩写:ICA) 是一种利用统计原理进行计算的方法。它是一个线性变换。这个变换把数据或信号分离成统计独立的非高斯的信号源的线性组合。独立成分分析是盲信号分离(Blind source separation)的一种特例。
之前不太清楚这是什么,今天看到《机器学习工程师必知的十大算法》里这一条还没听过用过。而看了个大致介绍,感觉和我的毕设有点契合,所以集中学习一下。
0 参考资料
1 简介
In signal processing, independent component analysis (ICA) is a computational method for separating a multivariate signal into additive subcomponents. This is done by assuming that the subcomponents are non-Gaussian signals and that they are statistically independent from each other. ICA is a special case of blind source separation.
中文不太好的维基:在统计学中,独立成分分析或独立分量分析(Independent components analysis,缩写:ICA) 是一种利用统计原理进行计算的方法。它是一个线性变换。这个变换把数据或信号分离成统计独立的非高斯的信号源的线性组合。独立成分分析是盲信号分离(Blind source separation)的一种特例。
2 定义
- 一句话,从多通道测量中得到的有若干独立信源线性组合成的观测信号中,将独立成分分解出来。
- 因为主成分分析只对符合高斯分布的样本点比较有效,所以ICA可以看成是主成分分析与因子分析的延展。
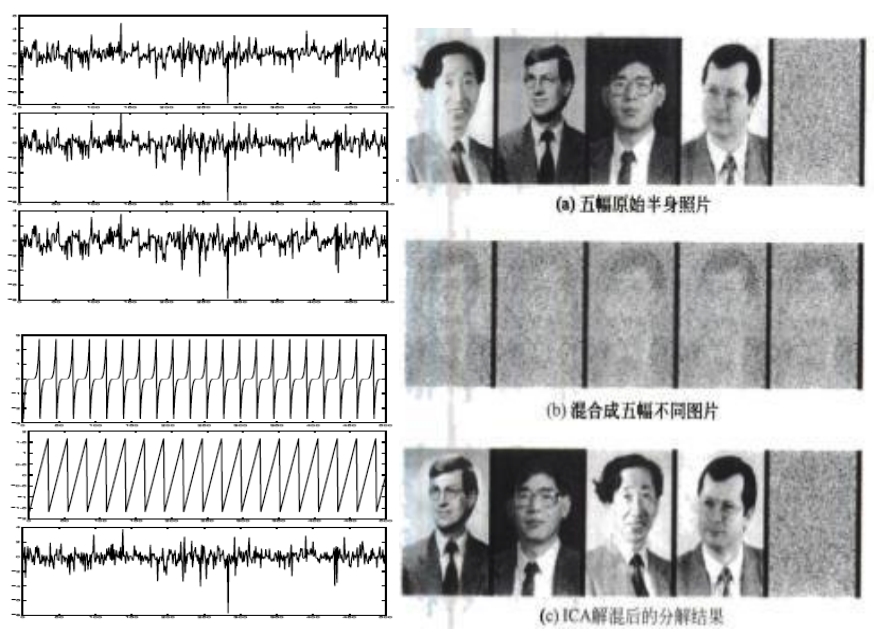
- 独立成分分析的最重要的假设就是信号源统计独立。这个假设在大多数盲信号分离的情况中符合实际情况。
- 即使当该假设不满足时,仍然可以用独立成分分析来把观察信号统计独立化,从而进一步分析数据的特性。
- 独立成分分析的经典问题是“鸡尾酒会问题”(cocktail party problem)。
- 该问题描述的是给定混合信号,如何分离出鸡尾酒会中同时说话的每个人的独立信号。
- An important note to consider is that if $N$ sources are present, at least $N$ observations (e.g. microphones if the observed signal is audio) are needed to recover the original signals. This constitutes the case where the matrix is square ($D=J$ , where $D$ is the number of observed signals and $J$ is the number of source signals hypothesized by the model). Other cases of underdetermined ($D<J$) and overdetermined ($D>J$) have been investigated.
- 当有$N$个信号源时,通常假设观察信号也有$N$个(例如$N$个麦克风或者录音机)。该假设意味着混合矩阵是个方阵,即$J = D$,其中$D$是输入数据的维数,$J$是系统模型的维数。对于$J < D$和$J > D$的情况,学术界也分别有不同研究。
- 独立成分分析并不能完全恢复信号源的具体数值,也不能解出信号源的正负符号、信号的级数或者信号的数值范围。
2.1 问题分类
Linear independent component analysis can be divided into noiseless and noisy cases, where noiseless ICA is a special case of noisy ICA. Nonlinear ICA should be considered as a separate case.
2.2 General definition
The data are represented by the observed random vector ${\boldsymbol {x}}=(x_{1},\ldots ,x_{m})^{T}$ and the hidden components as the random vector ${\boldsymbol {s}}=(s_{1},\ldots ,s_{n})^{T}.$ The task is to transform the observed data using a linear static transformation ${\boldsymbol {W}}$ as ${\boldsymbol {s}}={\boldsymbol {W}}{\boldsymbol {x}}$, into an observable vector of maximally independent components ${\boldsymbol {s}}$ measured by some function $F(s_{1},\ldots ,s_{n})$ of independence.
简单讲,就将观察到的向量通过线性变换,使其本身的隐含成分的独立成分被分离。
2.3 Generative model
2.3.1 Linear noiseless ICA
The components $x_{i}$ of the observed random vector ${\boldsymbol {x}}=(x_{1},\ldots ,x_{m})^{T}$ are generated as a sum of the independent components $s_{k}$, $k=1,\ldots ,n$:
$$
x_{i}=a_{i,1}s_{1}+\cdots +a_{i,k}s_{k}+\cdots +a_{i,n}s_{n}
$$
weighted by the mixing weights $a_{i,k}$.
The same generative model can be written in vector form as $\boldsymbol{x}=\sum_{k=1}^{n} s_{k} \boldsymbol{a}{k}$, where the observed random vector ${\boldsymbol {x}}$ is represented by the basis vectors $\boldsymbol{a}{k}=\left(\boldsymbol{a}{1, k}, \ldots, \boldsymbol{a}{m, k}\right)^{T}$.
The basis vectors $\boldsymbol{a}{k}$ form the columns of the mixing matrix $\boldsymbol{A}=\left(\boldsymbol{a}{1}, \ldots, \boldsymbol{a}{n}\right)$ and the generative formula can be written as $\boldsymbol{x}=\boldsymbol{A} \boldsymbol{s}$, where $\boldsymbol{s}=\left(s{1}, \dots, s_{n}\right)^{T}$.
2.3.2 Linear noisy ICA
With the added assumption of zero-mean and uncorrelated Gaussian noise $n \sim N(0, \operatorname{diag}(\Sigma))$, the ICA model takes the form $\boldsymbol{x}=\boldsymbol{A} \boldsymbol{s}+\boldsymbol{n}$.
2.3.3 Nonlinear ICA
The mixing of the sources does not need to be linear. Using a nonlinear mixing function $f( \cdot| \theta)$ with parameters $\theta$ the nonlinear ICA model is $x=f(s | \theta)+n$.
3 实战
操作上的感觉是这样的,
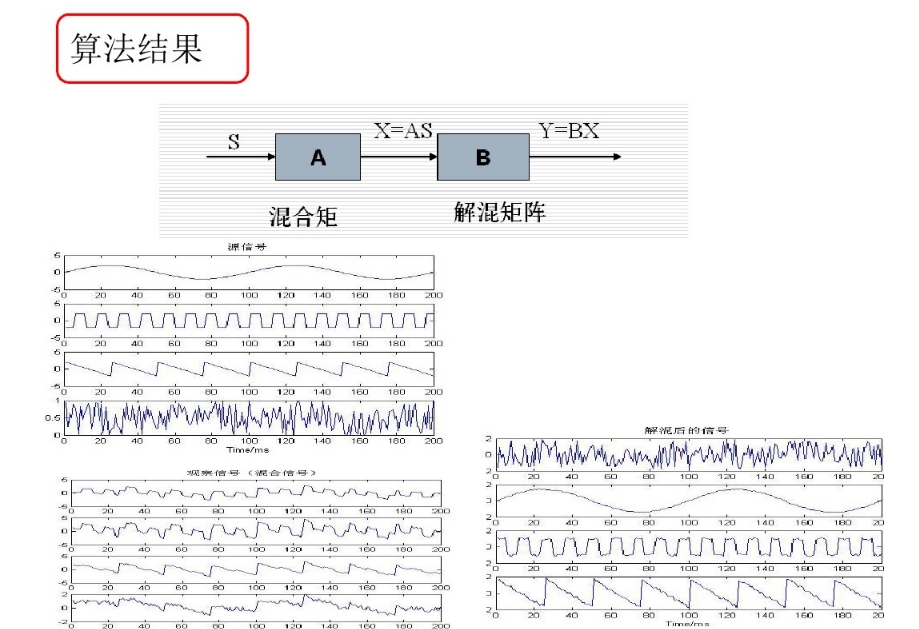
图/百度百科
独立成分分析存在各种不同先验假定下的求解算法。而且,经过ICA处理后,重建的数据幅度可能发生变化,自身也可能翻转。
fastica是sklearn.decomposition下的算法。
Implemented using FastICA: A. Hyvarinen and E. Oja, Independent Component Analysis: Algorithms and Applications, Neural Networks, 13(4-5), 2000, pp. 411-430
前提: 观测数据为数个独立、非高斯信号的线性组合。
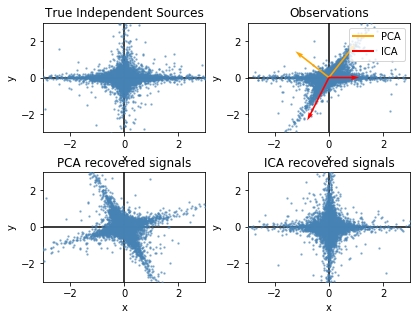
此外,白化的意思是,使用白化矩阵消除各观测间的二阶相关性。这可以有效地降低问题的复杂度,而且算法简单,用传统的PCA就可完成。
对于sklearn,我看到了两个包,
decomposition.FastICA([n_components, …]): FastICA: a fast algorithm for Independent Component Analysis.decomposition.fastica(X[, n_components, …]): Perform Fast Independent Component Analysis.
其步骤为

下面先看FastICA的示例,
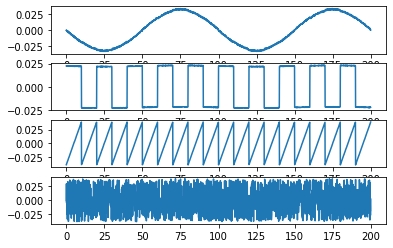
3.1 FastICA on 2D point clouds (sklearn examples)
1 | # -*- coding: utf-8 -*- |
3.2 网友的fastICA
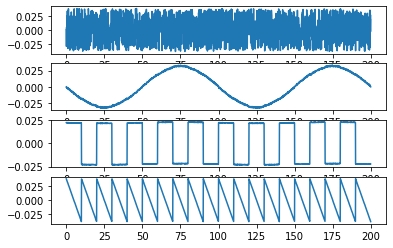
1 | # -*- encoding:utf-8 -*- |
4 应用
- optical Imaging of neurons
- neuronal spike sorting
- face recognition
- modelling receptive fields of primary visual neurons
- predicting stock market prices
- mobile phone communications
- color based detection of the ripeness of tomatoes
- removing artifacts, such as eye blinks, from EEG data.
- analysis of changes in gene expression over time in single cell RNA-sequencing experiments.
- studies of the resting state network of the brain.
都看到这儿了,不如关注每日推送的“科文路”、互动起来~