文章来自微信公众号“科文路”,欢迎关注、互动。转发须注明出处。
接前回,本文补上What makes TPUs fine-tuned for deep learning? | Google Cloud Blog中的最后一部分和开头后组成全文。
由谷歌从零开始设计的张量处理单元 (TPU) 是一种定制的 ASIC 芯片。它用于负载机器学习工作,并已为谷歌的几个主要产品助力:翻译、照片、搜索助手和邮箱。借助 Cloud TPU,在 Google Cloud 上,所有开发人员和数据科学家在使用前沿的机器学习模型时也可以利用到 TPU 可扩展且易于使用的优势。在最新一期的年度会议 Google Next ‘18 上,我们宣布 Cloud TPU v2 已面向包括免费试用帐户在内的所有用户全面推出,同时发布了 Cloud TPU v3 alpha 版。
神经网络是如何工作的?
让我们看看机器学习需要什么样的计算,特别是神经网络。
例如,假设我们使用单层神经网络来识别手写数字的图像,如下图所示:
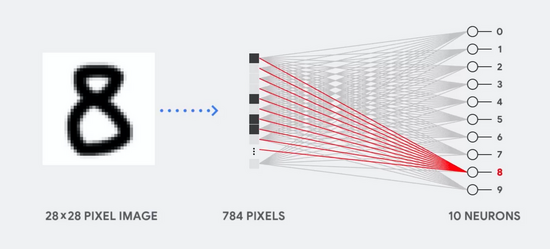
如果图像是 28 x 28 灰度像素的网格,则可以将其转换为具有 784 个值(维度)的矢量。识别数字“8”的神经元将这些值和参数值相乘(上面的红线)。
这些参数作为“过滤器”从数据中提取特征,从而体现图像和数字“8”的形状的相似性,其过程如图:

这个就是神经网络对数据分类的最基本解释:将数据和它们各自的参数相乘(上面有颜色的点),然后将它们全部相加(右侧得到的点)。如果得到的分数最高,就意味着找到了输入数据与其对应参数之间的最佳匹配,也就很可能是正确答案。
简而言之,神经网络需要数据和参数之间的大量乘法和加法。我们经常将这些乘法和加法组织成矩阵乘法,就是你在高中代数中遇到过的那些。
所以问题就变成了如何以更少的功耗尽可能快地执行大型矩阵乘法。
CPU 是如何工作的?
什么是冯诺依曼瓶颈?CPU为什么不适宜做深度学习中的运算?
CPU 是基于冯诺依曼架构的通用处理器。这也就是说 CPU 与软件和内存一起工作。
CPU 的最大益处是它的灵活性。凭借其冯诺依曼架构,你可以在上百万种场景下加载任何类型的软件。你可以使用 CPU 在 PC 中进行文字处理、控制火箭发动机、执行银行交易或使用神经网络对图像进行分类。
但也就是由于 CPU 的灵活,硬件设备只有到它从软件中读到下一条指令的时候,它才知道自己要做什么。 CPU 必须在单次计算中将结果存储在 CPU 内的内存中(也就是所谓的寄存器或 L1 缓存)。这种内存访问是 CPU 架构的缺点,被称为冯诺依曼瓶颈。尽管大规模的神经网络计算意味着接下来的步骤是完全可预测的,但每个 CPU 的算术逻辑单元 (ALU),控制乘法器和加法器的组件)依序执行,每一次都访问内存。这限制了总吞吐量,并将增加能耗。
GPU 是如何工作的?
为了获得比 CPU 更高的吞吐量,GPU 使用了一个简单的策略:何不在一个处理器中配上几千个 ALU?当下的 GPU 通常在单个处理器中配备了 2,500–5,000 个 ALU,这就意味着可以同时执行几千个乘法和加法运算。
这种 GPU 架构适用于具有大规模并行性的应用程序,例如神经网络中的矩阵乘法。实际上,在深度学习的典型训练工作负载上,GPU 的吞吐量比 CPU 高出一个数量级。这也就是此时,GPU 是深度学习中最流行的处理器架构的原因。
但是,GPU 仍然是一个“通用”处理器,因为需要它支持各种各样的应用程序。这又回到了我们的基础问题——冯·诺依曼瓶颈。对于几千个 ALU 中的每一次计算,GPU 都需要访问寄存器或共享内存来读取和存储中间计算结果。由于 GPU 在其数千个 ALU 上更多的时候执行的是并行计算,因此它也相应地花费了更多的能耗来访问内存,同时复杂的布线也增大了 GPU 的面积。
TPU 是如何工作的?
当谷歌设计 TPU 时,他们做了一个 DSA(特定领域的架构)。也就是说,我们把它设计成了一个专门用于神经网络工作的矩阵处理器,而没有设计一个通用的处理器。TPU 不能运行文字处理软件、不能控制火箭引擎、也不能执行银行交易,但它可以以惊人的速度处理神经网络的大量乘法和加法运算,而消耗的功率和占用的访存却小得多。